基本介绍
Bigtable是一个分布式的数据库,
它的出现主要是因为传统的关系型数据库在面对大量数据(PB级别)时不具有扩展性。
Bigtable在谷歌内部得到了广泛使用,
Apache HBase 是它的开源实现。
数据格式
可以把一个Bigtable当成一个持久化的,分布式的,多维的map。
它的值通过(rowkey, columnkey, timestamp)来索引。
其中rowkey,columnkey和值都可以是任意的字符串。
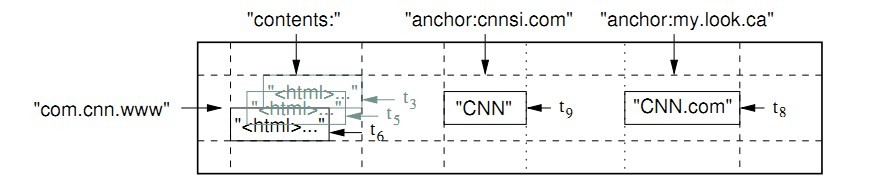
如下图所示。
在上图中,rowkey是com.cnn.www。
在Bigtable中,对row的操作是原子(atomic)的。
在Bigtable中,数据的保存顺序是通过rowkey的字典序来维持的,
基于这个特点,可以通过挑选合适的rowkey把相关的数据放在一起。
比如上图,通过使用倒序的主机名作为rowkey,
可以把同一域名下的网页放在一起。
几个row组合起来形成一个tablet,
一个table由一个或多个tablet组成。
columnkey通过column family来进行划分,
如上图,anchor就是一个column family,它有两个column key:
anchor:cnnsi.com和anchor:my.look.cn。
contents也是一个column family, 它只有一个column key,
就是contents:。column family是访问控制的基本单位。
每一个column key必须以column family:qualifier的格式命名。
对于同一个rowkey和columnkey的组合,
Bigtable根据不同的timestamp保存了不同的值。
通常,会保存最近的几个版本(具体的版本数用户可以指定),
过期的数据会被垃圾回收掉。
API
Bigtable的API非常简单,下面是两个使用API的例子:
写Bigtable 1
2
3
4
5
6
7
8
// Open the table
Table * T = OpenOrDie ( "/bigtable/web/webtable" );
// Write a new anchor and delete an old anchor
RowMutation r1 ( T , "com.cnn.www" );
r1 . Set ( "anchor:www.c-span.org" , "CNN" );
r1 . Delete ( "anchor:www.abc.com" );
Operation op ;
Apply ( & op , & r1 );
上面的代码段对rowkey="com.cnn.www"的行,
将columnkey="anchor:www.c-span.org"的列的值设置为CNN,
同时删除columnkey = "anchor:www.abc.com"的列。其中Apply()是原子操作。
读Bigtable 1
2
3
4
5
6
7
8
9
10
11
12
Scanner scanner ( T );
ScanStream * stream ;
stream = scanner . FetchColumnFamily ( "anchor" );
stream -> SetReturnAllVersions ();
scanner . Lookup ( "com.cnn.www" );
for (; ! stream -> Done (); stream -> Next ()) {
printf ( "%s %s %lld %s \n " ,
scanner . RowName (),
stream -> ColumnName (),
stream -> MicroTimestamp (),
stream -> Value ());
}
上面的代码段遍历rowkey="com.cnn.www"的行中column family="anchor"的所有列的所有版本。
实现
Bigtable使用了几个部件构建而成:
组成部分
和GFS类似,Bigtable也由三个部分组成,分别是:
client:用于和应用程序交互
一个master: 管理整个系统,要做的工作包括分配tablet,
负载均衡,垃圾回收,处理schema的变化。
很多的tablet server:一个tablet server负责多个tablet,
client对于tablet的读写请求直接与tablet server进行交互。
需要注意的是,与GFS不一样,
关于tablet的位置信息client不需要通过master就可以知道(接下来就会提到),
所以大部分情况下client都不需要和master交互,
这样master上的压力更小了。
Tablet的位置
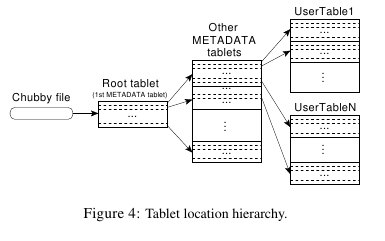
Bigtable使用一个三层的结构来存放tablet的位置,
如下图所示。(论文上说这个和B+树比较像,
我倒觉得用inode来类比更加好理解)
首先,一个Chubby File保存了root tablet的位置。
root tablet是一个特殊的METADATA table,
它保存了所有其他METADATA tablet的位置。
每一个METADATA又保存了user tablet的位置。
所以,顺着这个结构走下来,就能找到任意的tablet的位置。
关于这个“位置”,我是这样理解的,
它应该是一个具体的tablet server的名字,
client知道了哪个tablet server之后就向那个tablet server发出请求。
如果是这样的话,把tablet重新分配之后master需要去更新这些保存位置的tablet。
这里还有几个计算:
如果一行占的空间是1KB,一个tablet的空间是128MB,
那么这样一个三层的结构能够保存的tablet的数目为$2^{34}$,
这个很容易理解,128MB / 1KB = $2^{17}$,两级下来就是$2^{34}$。
客户端会缓存住tablet的location,这样就不用每次都去读这个层级的结构。
如果客户端没有缓存,那么它读取一个tablet需要3次和tablet server的交互
(读root,METADATA,user tablet各一次)。如果缓存过期了,
最多需要6次和tablet server的交互(对于这个,我的理解是,如果客户端缓存了root tablet的location,
但是它过期了,那么它首先顺着这个结构下去,需要3次,然后发现不对,
又重新向Chubby得到root的位置,又再次顺着这个结构下去3次,
一共6次)。
Tablet的分配
一个tablet一次只会被分配给一个tablet server,
master保存下面的信息:
哪些tablet server是正常工作的(alive)
哪些tablet被分配给哪些tablet server
哪些tablet没有被分配(这个只是暂时的,master会把这些tablet分配好,外面看不到这个状态?)
当一个tablet server启动时,
它会去获取Chubby的某个特定目录下的一个文件(一个tablet server唯一的对应这个目录下的一个文件)的互斥锁。
master通过检查这个目录查看哪些tablet server是alive的。
tablet server如果丢失了这个互斥锁,那么它会尝试重新获取,
如果这个文件不存在了,tablet server永远都拿不到这个锁了,
那么它会自动停止。
如果tablet server不工作了,它会释放这个锁,
这样master就知道它没有工作了,把它上面的tablet分配给其他的tablet server。
master会频繁地和那些正常工作的tablet server进行通信来获取它们的状态,
如果tablet server告诉master它失去了锁或者无法和这个tablet server进行通信,
那么master会尝试获取这个tablet server对应的文件锁,
如果能够拿到这个锁,说明Chubby能正常工作,
而这个tablet server要么死掉了要么不能和Chubby交互,
那么master就删除这个tablet server对应的文件,
这样这个tablet server就没用了,
然后master把这个tablet server上的tablet分配给其他的tablet server。
在master启动时,它会执行下面的步骤:
首先,它会去Chubby上获取master锁,确保同一时间只有一个master工作
然后,扫描Chubby上的目录(就是上面提到的目录,所有tablet server对应的文件都在这个目录下),
知道哪些tablet server是alive的
然后,和每个alive的tablet server交互,知道哪些tablet已经被分配了
最后,便利tablet位置的三层结构(Figure 4),知道一共有哪些tablet,
然后把这些tablet分配给tablet server。
这里有一个问题是,如果METADATA的tablet没有被分配,
那么它就不能被读取,那么第4步就没法进行了。
这个问题可以这样解决,如果需要读取某个tablet时它还没有被分配,
那么先把它分配给某个tablet server,然后就可以继续接下来的步骤。
当下面的情况发生时,tablet的分配情况要进行调整:
tablet被创建或删除
tablet被合并
tablet被切分成两个tablet
前面两种情况都是在master进行的,所以master直接进行调整就行,
而第三种过程是在某个tablet server上进行的,
master怎么知道的呢?
当tablet server对tablet进行切分时,
它首先在METADATA的tablet上记录下这个新的tablet,
然后通知master发生了改变。
如果这个通知丢失了,
那么当master去请求这个被切分的tablet时,
tablet server会发现这个tablet的METADATA table只是请求的METADATA的一部分,
就知道发生了切分,然后告诉master。
Tablet的保存
下面来看下一个tablet具体是如何保存的。
根据这篇博客 ,
要保存一个tablet,有这么几个部分:
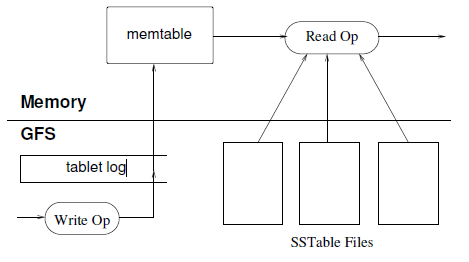
主SSTable,就是持久化的不可变的哈系表,保存在GFS上
memtable,在内存中记录最近的修改操作
commit log,修改记录,分为compacted和uncompacted(待会会说明)
次SSTable(为了区分两种SSTable,我用了“主”, “次”,不是重要性的区分),
这种SSTable是memtable的持久化版本,次SSTable的存在是为了加快recovery的速度,
因为recovery需要从commit log恢复memtable,同时可以释放memtable的内存
有了这几个部分,对tablet的操作也就变得容易了,
对于写操作,只需要记录把操作记录在commit log中,
同时写入memtable。对于读操作,
由于数据不仅仅保存在主SSTable上,
还需要结合memtable和次SSTable来进行。
Compactions
Compaction主要是为了解决上面过程中出现的问题,它分为3种:
minor compaction: 这个操作就是把memtable中的内容保存到SSTable,
释放memtable的内存,同时减小recovery时需要读取的commit log的数目,
已经被保存到次SSTable上的操作对应的commit称为compacted,
recovery时只需要从uncompacted的commit log中恢复就行了。
merge compaction:
因为每次读取操作时都需要读取主SSTable和相关的次SSTable,
所以次SSTable的数量不能太多,因此,
master会把一些次SSTable组合成一个新的次SSTable。
major compaction:
master把次SSTable和memtable中的内容整合到SSTable里,
这样,就能回收掉修改的和删除的记录所占的空间。
优化
Locality groups
client可以把一些列组放在一起形成一个locality group,
在每一个tablet里面,会为每一个locality group生成一个单独的SSTable,
使用locality group的好处是:
可以提高读的性能,比如把网页的contents放在一个locality group,
而metadata放在另外一个locality group,
这样读取metadata时就不需要读取网页的内容。
可以对于不同的locality采取不同的调优参数。比如,
可以把有些locality group的SSTable放入内存。
Cache
为了提高读性能,tablet server采用了两种级别的cache:
Scan Cache,缓存从SSTable返回的key-value对
Block Cache,缓存从GFS读回来的SSTable的block
Bloom filters
读操作需要结合SSTable和memtable,因此,
可以通过bloom filter来制定某些locality group的数据不可能存在于某些SSTable,
这样就可以减少需要读取的SSTable的数量。
Bloom filter一般保存在tablet server的内存中。
Commit log实现
在Bigtable中,每一个tablet server只保存一个commit log,
这个commit log保存了所有的tablet相关的log。这样做的好处是:
如果每个tablet一个commit log,就会导致同时有很多写请求发到GFS,
这样就会很多的磁盘seek。
这样限制了group commit的作用,
因为只有同一个tablet的写操作才能被合并成一个到一个group commit。
所有tablet的commit log组合成一个文件增加了恢复的复杂性,
因为这样不同的tablet可能被迁移到不同的tablet server,
这样所有相关的tablet server都需要读取这个commit log来获取tablet的信息,
这个commit log会被重复读多次。
解决这个问题的一个办法是在recovery时,
先把commit log使用<table, row name, log sequence number>作为key进行排序,
这样一个tablet的commit log就是连续的,可以通过一次seek,
然后连续读就可以得到。
这个排序的过程也可以通过把这个commit log分成几块,然后并发地进行排序来加快速度。
为了避免GFS集群中由于网络原因或者load情况带来性能上的波动,
通常使用两个线程来完成写commit log的操作,
每一个线程有自己的commit log文件,
同一时课只有一个线程在写,
如果一个线程写出现了性能上的问题,
就切换到另外一个线程(因为两个线程使用了不同的文件,
可能分布到不同的chunkserver)。同时,
使用序列号来消除重复的commit log。
加快recovery
如果master把tablet从一个tablet server移到另一个,
源tablet server可以进行一次minor compaction,
这样uncompacted的commit log就减少了很多,
因为这个过程中可能会有其他的写操作,
所以在upload这个tablet时,
可以再进行一次非常快的minor compaction,
这样就不要进行recovery了。
不变性
利用SSTable的不可变性带来了以下的方便:
缓存。
memtable是唯一可变的数据结果,对它使用copy-on-write 来消除读写冲突。
回收垃圾只需要回收SSTable就好了。
在split时,child tablet可以使用parent tablet的SSTable。