简介
对于计算机系的同学来说,MapReduce这个词应该并不陌生, 现在是所谓的“大数据时代”,“大数据”这个词被炒得非常热。 何为“大数据”?随着互联网的发展,现在的数据越来越多, 给原先的技术带来了两方面的挑战,一是存储, 如何存储这些PB级别的数据, 二是分析, 如何对这么大的数据进行分析, 从中提取出有用的信息。
MapReduce就是一个对大数据进行分析的框架。
使用MapReduce,用户只需要定义自己的map函数和reduce函数,
然后MapReduce就能把这些函数分配到不同的机器上去并行的执行,
MapReduce帮你解决好调度,容错,节点交互的问题。
这样,一个没有分布式系统编程经验的人也可以利用MapReduce把自己的程序放到几千台机器上去执行。
map和reduce都是来自于函数式编程的概念,map函数接受一条条的纪录作为输入,
然后输出一个个<key, value>对,reduce函数接受<key, values>对,
(其中values是每一个key对应的所有的value),通过对这些values进行一个“总结”,
得到一个<key, reduce_value>。
比如拿经典的WordCount例子来说,对于文本中的每一个单词word,
map都会生成一个<word, 1>对(注意如果一个文本中一个单词出现多次就生成多个这样的对),
reduce函数就会收到<word, 1,...>这样的输入,它的工作就是把所有的1都加起来,
生成一个<word, sum>。
MapReduce函数基于键值对进行处理,看起来很简单, 那很多的分析任务不仅仅只是简单的Wordcount而已,能够使用这两个函数来实现吗? 幸运的是,很多的大规模数据分析任务都能通过MapReduce来表达, 这也是为什么MapReduce能够作为一个框架被提出的原因, 在最后一个部分中会给出一些更加复杂的使用MapReduce的例子。
架构
在大概了解了MapReduce之后,我们来看一下它到底是怎么实现的。 我们首先看一下一个MapReduce任务执行完需要经过那些流程, 然后再看一下在实现MapReduce的时候需要考虑的几个因素。
基本流程
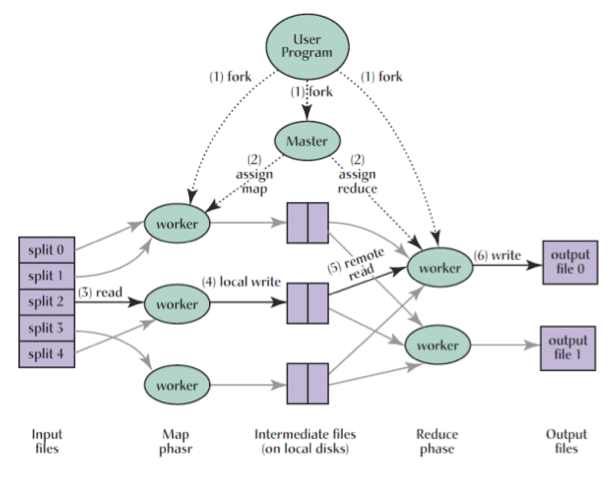
我们首先假定把一个任务分成M个mapTask和R个reducetask,
如上图,
整个任务的执行过程如下:
-
首先根据
map的数量把原来的数据分成M个splits,每一个split对应一个maptask。 -
在集群的节点上启动
master,M个maptask和N个reducetask,master把split分配给相应的maptask。需要注意的是, 一个集群的节点(又称作一个worker)上可能有多个maptask, 也有可能maptask和reducetask在同一个worker。 -
每一个
maptask读取自己的split,根据用户定义的map函数生成<key value>对, 把结果保存在本地文件中, 根据key的不一样,结果被写入到R个不同的文件。 这些文件的位置会告知给master,然后master再告知给相应的reducetask。 -
当一个
reducetask被告知这些文件的位置时,它通过远程调用读取这些文件的内容, 当和这个reducetask相关的所有文件都被读到之后,它把这些内容按照key进行一个排序, 然后就能保证同一个key的所有values同时被传给reduce。 -
reducetask使用用户定义的reduce函数处理上述排序好的数据, 将最终的结果保存到一个Global File System(比如GFS), 这是为了保证数据的可靠性。
文件的保存
在上述的过程中,我们看到maptask的结果被保存在本地,
而把reducetask的结果保存在具有可靠性保证的文件系统上。
这是因为maptask产生的是中间结果,当这些结果被reduce之后,
就可以被扔掉,不需要备份,这样可以节约磁盘空间。
而reducetask产生的是最终结果,需要一定的可靠性保证。
split的粒度
在对一个任务进行划分时,需要考虑split的粒度:
-
如果split太小,M就会很大,
master需要纪录的数据就会很多, 就会消耗很多master的内存。 -
如果split太大,一方面调度不具有灵活性, 因为调度是以split为单位的,一个较大的task无法被分割放到其他空闲的worker上去执行。 另一方面无法利用
locality进行调度, 因为maptask的输入文件一般保存在分布式文件系统上,master在调度时尽量把一个split分配到较近的节点上去执行, 如果split太大超过了一个文件block的大小, 这样可能两个block在不同的节点上,甚至跨了不同的机架, 这样无法利用locality了。
所以,在实际应用中,split的大小为一个block。
容错
由于MapReduce被分布到上千台机器上去执行, 错误是不可避免的。 MapReduc需要在节点发生故障时进行处理。
当一个节点发生故障,
在这个节点上的所有的maptask都需要重新执行,
因为maptask的结果是保存在节点本地的,
节点发生故障之后,这些结果就不可用了。
而成功执行的reducetask就不需要重新执行了,
因为它的结果是保存在分布式文件系统上,
可靠性是可以保证的。
常见应用
矩阵向量乘法
假设有一个的矩阵M, 它和一个n维列向量v的乘积是一个m维的列向量x,有
可以根据j,把M按列分成k块,把v也对应分成k块,
每个M块和对应的v块被分给一个maptask,
maptask生成的结果为对,
reducetask把每一个i对应的所有加起来。
关系代数运算
关系数据库表的Join,Selection,Projection, Union, Intersection, Difference,Group And Aggregation等操作都可以使用MapReduce来实现。
值得一提的是,对于Join运算,比如链接关系R(a, b)和关系S(b, c),
在生成以b为键的键值对时,需要指定来自于哪一个关系,
比如关系R生成的键值对的形式为<b, (R, a)>,
这样reduce时就可以根据这个信息进行组合。
矩阵乘法
假设有一个的矩阵M, 和一个的矩阵N, 它们的乘积是一个的矩阵P, 有:
矩阵M和矩阵N的乘法可以看成是关系M(I, J, V)和关系N(J, K, W)先进行一次Join, 再进行一次Group And Aggregation之后的结果, 因此可以直接通过两次MapReduce进行矩阵的乘法运算。
如果想要一次MapReduce就得到结果,可以在map时以(i, k)为键生成键值对,
同样的,需要指明来自于矩阵M还是矩阵N,因此,相应的键值对的格式分别为
(对于矩阵M),(对于矩阵N)。
reduce时进行相应的组合。